
第37回:「知徳報恩の話(3)」
コラム<はじめに>
友達が「歯が痛い」と言う。虫歯か?親知らずか?そんな辛そうな様子を放っておくわけにもいかず、Googleの検索窓に「歯医者」と入れてみる。
おー。出てくる出てくる(笑)。
◯◯歯科クリニック
4.0 ☆☆☆☆★ (44) 歯科医院
銀座◇丁目△ー□ 03-xxxx-xxxx
歯科医院のリストが表示された。Googleは、ユーザーの位置情報を元に、近くの歯科医院を多数教えてくれる。画面上部に表示された地図上に対応する位置も示されている。上記はそのひとつ。平均の星の数は4.0。評価も44件あるらしい。クリックしてみると、口コミが表示される。雰囲気も良さそう。ここから徒歩圏内か…
※実名表示を避けるため、スクリーンショットの引用は控えます(笑)。
Google検索(Google Search)はカシコイ。何か調べ物があるときには、ともあれGoogle検索に聞いてみる、なんてことは当たり前になった。
Google検索も「知徳報恩」を考えるヒントに溢れている。第35、36回で紹介したように、「顕名市場」におけるデータ戦略を考えるためには「知徳報恩」型のデータエコノミーを理解することが早道である。今回は、Google検索の仕組みを紐解きながら、そこでいかに価値共創が行われ、どのようにユーザーに還元されているかを考えてみたい。
今回は「信頼」についても考察する。第36回は、サイバー文明の到来と、その主要な要素である「富」を構成するのが「信頼」であると述べた。実は「知徳報恩」モデルでも「信頼」が重要な意味を持つ。本稿では、データビジネスを考える上で「信頼」がどのような役割を果たすのかを考えてみたい。
<Google検索>
Googleと聞いて最初にイメージするのは「検索」だろう。昔、「すごい検索サービスが登場した」と教えられて以来、かれこれ20年以上、私もGoogle検索(Google Search) を愛用している。
Google検索を使う人は多い。2022年現在、世界の検索市場シェアの90%以上を誇り、そのアクセス数は1日あたり85億回を超えるらしい。シンプルな検索窓、スピーディな回答が最大の特徴かもしれない。
https://www.linkedin.com/pulse/10-google-search-statistics-you-need-know-2022-paul-slaney/
Google検索の精度は年々向上している。精度は、検索したい情報にたどり着ける確率、といえばよいだろうか。Googleが登場した1998年には、なかなか想定している結果が得られなかったというが、その後、Googleは急速に進化した。今では、数ある検索エンジンの中でも圧倒的な検索精度なのではないか、と感じさせる(主観だが、笑)。
Google検索ではいろいろなアルゴリズムが使われている。例えば、検索結果の優先順位付けに、次のような情報が参照されていることは覚えておくと良いかもしれない。
- 検索キーワードと一致するサイトのコンテンツ
- サイトのタイトルやメタデータ
- サイト内のリンクの構造
- サイトのアクセス頻度やアクセス元
- サイトのロードスピード
- モバイルフレンドリーであるか
Google検索の精度向上にはユーザーからのインプットも大きな役割を担う。例えば、上記のリストの中で「サイトのアクセス頻度やアクセス元」の情報は、ユーザーの行動情報を参照する。加えて、実は、他にもさまざまなユーザーからのインプットが参照される。いくつかの代表的な例をみてみよう。
当然だが、Google検索ではユーザーが入力した「検索ワード」を参照する。Google検索は、検索ワードに関連性の高いウェブページを紹介してくれる。結果のページに表示されるGoogle広告(旧Google AdWords)は、検索窓に入力した検索ワードに関連性の高い広告を表示することを強みとする。検索ワードはユーザーの興味の対象なので、広告効果も高いことが期待される(実際、広告の表示に対する反応率 ≒ コンバージョンレートは高い)。
ユーザーの位置情報も参照される。例えば、Google検索に「温泉」や「居酒屋」と入力すると、自分がいる場所を起点に近くにある温泉や居酒屋を教えてくれる。スマホではGPS情報を参照して、PCなどでGPS情報が参照できない場合にはWiFi情報を参照してユーザーの位置情報を推測して、できる限り、ユーザーにとって最適な検索結果を返そうとする。位置情報の参照時は、前回(第36回)紹介したGoogle Mapとも連動する。
ユーザーから明示的にレビューや口コミコメントが入力されることもある。冒頭の例は、歯医者というキーワード(歯科医院、など類似ワードにも自動的に紐付けされる)、ユーザーの位置情報、加えてユーザーからのレビューと口コミが参照されていることがわかる。
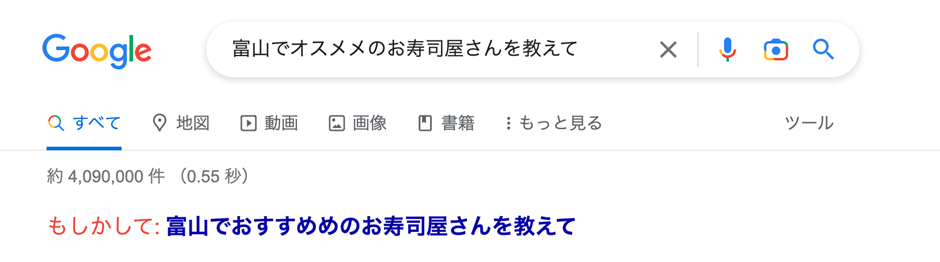
自然言語も貴重なインプットである。最近のGoogle検索は、自然言語に近い文章も受け付けてくれる。例えば「富山でオススメのお寿司屋さんを教えて」とGoogle検索で入れてみてほしい。GoogleがAI(人工知能)の技術に長けているのは有名だが、今では自然言語の構文解析も当たり前にこなす。友達に聞くのと同じように「問いかけ」られるのは嬉しい。
Google検索は「入力ミス」の検出もしてくれる。AIは誤入力を自動的に検出し、近い「問い」を予測してくれる。例えば「富山でオスメメのお寿司屋さんを教えて」と入力すると、「もしかして:富山でおすすめのお寿司屋さんを教えて」と表示し、その検索結果を返してくれる。
<Google検索と知徳報恩>
Google検索における「知徳報恩」について考えてみよう。前回までの復習になるが、
「社会に貢献し、社会から報いられる」
の考え方が「知徳報恩」型データエコノミーの基本である。サービスとデータの視点では、
「ユーザーが自身のデータをコミュニティや事業者と共有することで価値共創に貢献し、
その結果としてより便利なサービスを享受する」
と考えると分かりやすい。Google検索において、ユーザーは、インプット情報をGoogleと(暗黙的に)共有することで、全体の検索精度の向上やユーザー体験の改善に寄与することになる。いずれも「知徳報恩」モデルで説明できる。
位置情報の参照はさらに分かりやすい。位置情報を参照してより良い検索結果を返してくれることはもちろんだが、その結果からアクセスされたサイト情報が、その場所での(将来的な)検索精度向上に寄与する。
レビューや口コミは説明の必要もないだろう。お店や施設を説明するための付加情報をユーザーが共有してくれることで、サービスの価値共創につながり、別のユーザーが検索した際に情報を参考にすることができる。
自然言語入力の共有は、Googleの自然言語処理のAIの学習を経て構文解析の精度があがると同時に、誤入力の検出を容易にする。Google検索の(さらにはGoogleが提供する多数の)自然言語の解析や誤入力の検出が秀逸なのは、長らく、GoogleのAIがユーザーから入力された文章を学習してきたからである。
なお、Google検索について特記しておきたいことがある。Google検索は、そのアルゴリズムを極めて頻繁に改善している。2021年に、Google検索は、700,000件を超えるテストを実施して、4,000件を超える検索機能改善を行った。平均して、1日に10件以上の機能改善が行われていることになる。注目すべきは、そのテストの実施方法である。Google検索には日に数十億ものアクセスがある。そのうちの、ほんの0.1%未満を対象に、Google検索の機能改善のテストを(常に)行っているという。つまり、ユーザーのインプットと、その検索結果へのアクセスは、Google検索にとっては検索精度改善のための重要な参照データになっている。その結果として、ユーザーはさらに精度の高い検索結果を得ることができるようになる、とも言えそうだ。
https://service.plan-b.co.jp/blog/seo/206/
https://www.google.com/search/howsearchworks/
https://japan.googleblog.com/2022/03/Search-AI.html
<デジタルと信頼>
前回、サイバー文明の主要な3要素の一つが「富=信頼」であると述べた(あとの2つは「中核的技術=デジタル技術」、「統治機構=プラットフォーム」)。近代工業社会に長く浸っていた我々には「富=カネ」の印象が強い。データだ、戦略だ、と言っても、ビジネスの話になると「結局はカネだろう」という声が聞こえてきそうだ。では、サイバー文明において「富=信頼」と考える所以はどこにあるのだろうか。
近代工業文明の時代は「カネ」が競争力の源泉だった。ピケティが「21世紀の資本論」で論じたように、資本主義の世界では、お金を元とする利益率rが成長率gより大きい限り(常に大きいのだが)お金があるところにお金が集まるのは必然だった。
サイバー文明における競争力の源泉はデータである。ここ数回「知徳報恩」型データエコノミーについて紹介してきた。注目したいのは、どの例も、ユーザーがコミュニティや事業者とデータを共有することで価値を「共創」することである。デジタル時代には、事業者が自らデータを集めるだけではなく、ユーザーがデータを共有してくれる仕組みと関係づくりが競争力に直結する。
サイバー文明では「信頼」があるところに「データ」が集まる。ユーザーが事業者とデータを共有しても良いと思えるだけの「関係」構築は必須である。逆に、データを悪用される・第三者に売られるといった懸念があるなど、信頼が置けない事業者に対しては、データを共有するモチベーションは一気に冷めてしまう。ユーザー心理として当然だろう。
なお、データ戦略を考えるうえではバランスも必要である。データを扱うサービスでは、ユーザーメリットと信頼の両方が必要であり、そのバランスを考える必要がある。大きなメリットがあればユーザーにデータを共有するモチベーションが生まれるし、また、少ないメリットでも圧倒的に信頼できるサービス・事業者であればデータを共有することは可能かもしれない。とはいえ、より多くの、幅広いデータを共有して価値共創に挑戦するのであれば、さらなる「信頼」の関係が必要になることは間違いない。
<おわりに>
今回も「知徳報恩」型のデータエコノミーについて考察した。匿名市場から顕名市場へのシフトを考える上で「データ」話は避けて通れない。顕名市場の特徴のひとつは、データに基づく価値の「共創」であり、その仕組みを理解する上で「知徳報恩」の考え方が大きな意味を持つ。
今回は「サイバー文明」の主要要素の一つである「富=信頼」についても考察した。データビジネスを考える上でなぜ信頼が重要になるのか。本稿では「信頼のあるところにデータが集まる」という視点から、ユーザーと事業者の間の信頼関係がデータビジネスの肝になることを説明した。
「信頼」の話は奥が深い。データビジネスを考える上で、信頼をどう築き上げていくべきか。次回も「知徳報恩」の事例を参照しつつ、「信頼」についてさらに深堀りして考察してみたい。
最後になるが、ChatGPTについても触れておこう。Google検索を脅かすと言われている、ChatGPT (OpenAIが提供するチャット型のジェネレーティブAIのサービス)が注目を集めている。検索の仕組みを根本から変える可能性がある、とも言われている。その仕組みや将来像は気になるところだ。今回は「知徳報恩」の解説をするためにGoogle検索に絞って話を展開したが、いずれ、ChatGPTがもたらす構造変革についても触れてみたい。
※本内容の引用・転載を禁止します。
